Research
Our primary objective is to conduct a thorough analysis of Optical Coherence Tomography (OCT) images to develop cutting-edge machine learning techniques that can address the everyday challenges faced by ophthalmologists in the diagnosis and research of retinal conditions. In order to achieve this, we are actively researching and exploring the latest advancements in deep learning methods, particularly in Retinal layer segmentation and SCR detection. Our current focus is on the following research problems:
Retinal layer segmentation (RLS)
OCT examination generates a series of retinal cross-sectional images or B-scans that are critical for retinal diagnostic studies. These studies primarily involve analyzing the distance between the retinal layers in the B-scans, which makes detecting the retinal contours a crucial task. To address this challenge, our research efforts are centered on developing a deep learning-based contour detection system that can accurately segment the retinal layers. By leveraging the power of advanced deep learning techniques, our system aims to achieve high levels of accuracy and precision, significantly improving the efficiency of retinal layer segmentation. Our ultimate goal is to enhance the diagnostic capabilities of OCT examinations and contribute to the development of more effective treatments for retinal conditions.
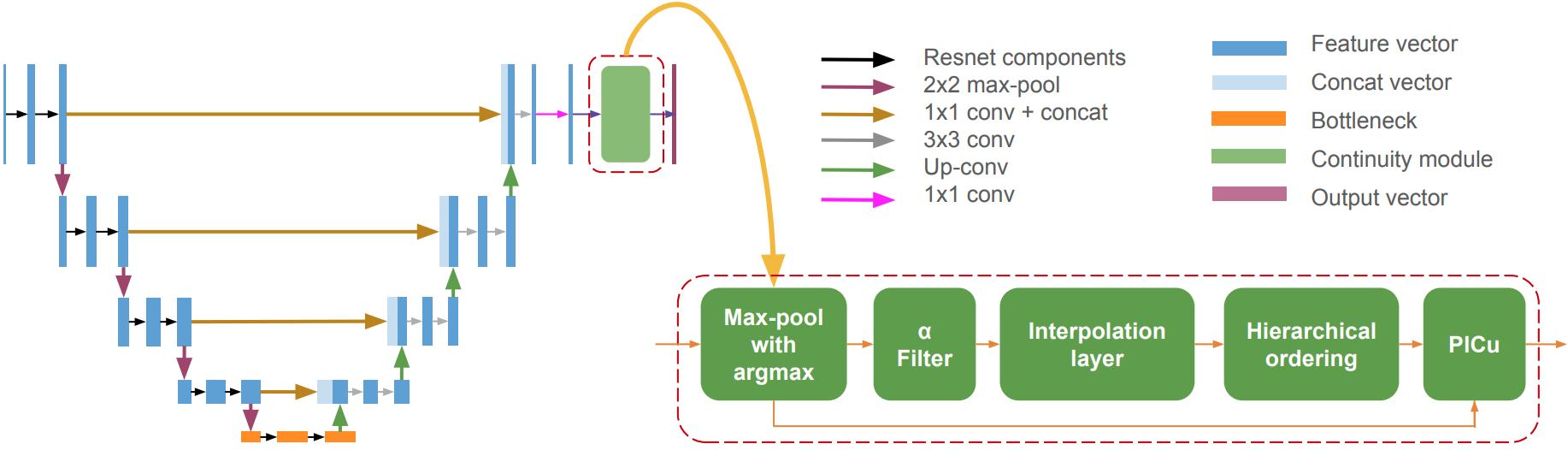
CU-Net: Continuous U-Net (CU-Net) is a sophisticated deep learning network that is based on the U-Net-like encoder-decoder architecture and is specifically designed for multi-class contour detection. One of the significant advantages of CU-Net is its ability to generate natural and uninterrupted contour lines, eliminating the need for post-processing the results, unlike other existing segmentation techniques. This is made possible due to a novel activation function, Polynomial Continuity Unit (PlCu), which seamlessly converts discrete signals into smooth and continuous contours. We have rigorously trained and tested our CU-Net using two benchmarked OCT datasets for retinal layer segmentation. The evaluations showed that CU-Net outperformed the existing state-of-the-art methods in RLS with regards to mean precision. The results thus indicate that our novel approach has a promising potential to advance the existing techniques in the field of retinal image analysis.
More details in our paper.
Video, poster, and other resources in supplemental materials.
Sickle Cell Retinopathy Detection
SCR is a condition characterized by the thinning of the inner retina in patients with Sickle Cell Disease. Ophthalmologists rely on retinal images obtained from OCT exams to diagnose SCR. However, the current manual diagnosis process, coupled with the lack of a comprehensive SCR dataset, has been a matter of concern among specialists and researchers studying the disease. To address this issue, our research endeavors to develop an effective deep learning-based system that can accurately detect and track changes in retinal thickness due to SCR. We have partnered with Nemours Children’s Hospital and distinguished ophthalmologist [Dr. Jing Jin] (https://www.nemours.org/find-a-doctor/5960-jing-jin-ophthalmology-wilmington) to collect and annotate high-quality OCT scans of children with Sickle Cell Disease. Our ultimate goal is to create a large-scale SCR dataset that can pave the way for further advancements in the diagnosis and treatment of this debilitating disease.
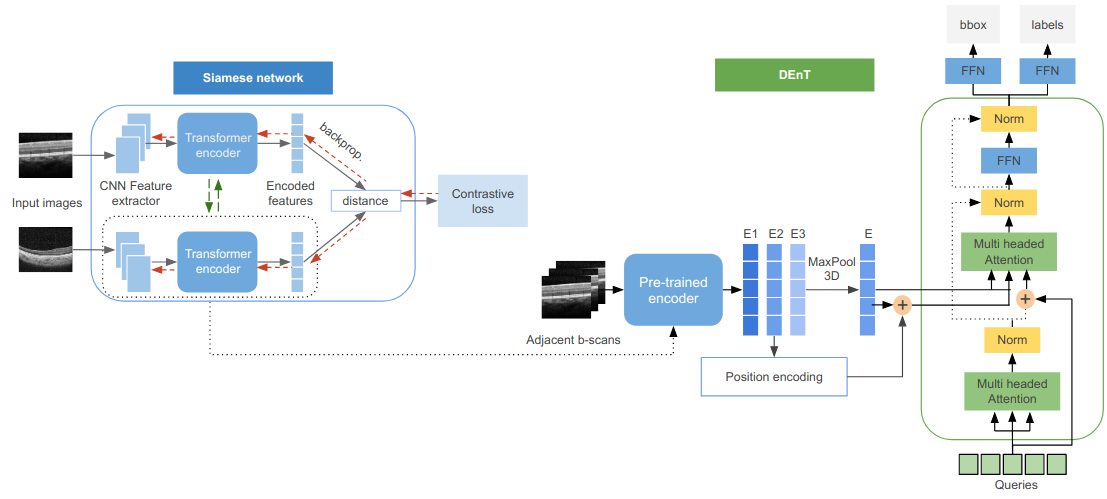
Detachable Encoder Transformer (DEnT) DEnT is a novel transformer-based system developed to improve the quality of Sickle Cell Retinopathy (SCR) detection. In contrast to previous systems that treated each B-scan as an independent entity, DEnT processes N adjacent B-scans simultaneously to incorporate the properties of neighboring B-scans while searching for SCR. This approach mimics the behavior of experts who refer to neighboring B-scans during manual detection of SCR instances. To achieve this, we modified the architecture of the Detection Transformer (DETR) decoder to compute the cross-attention matrix between N adjacent B-scans. The DEnT encoder calculates and combines the attention embeddings of each of the N B-scans, while the decoder queries this combined embedding using the positional encoding of one of the N B-scans. The performance of DEnT relies on the encoder’s ability to capture the intrinsic features of the retinal layers common to the N adjacent B-scans. To optimize this process, we developed a self-supervised pre-training method for the DEnT encoder using a siamese network that learns to differentiate between neighboring and unrelated B-scans. During pre-training, the encoder learns to focus on the subtle differences between two B-scans, such as the shape and thickness of retinal layers. Our evaluation of DEnT on the same training and testing dataset revealed superior performance compared to previous methods.
Relevant resources in supplemental materials.
Extisting object detection methods: As a precursor to our deep learning-based solution for SCR detection, we conducted an initial investigation using state-of-the-art object detection algorithms, including YOLO, FasterRCNN, and DETR, to establish a baseline. Given the lack of existing machine learning approaches for SCR detection, we leveraged these algorithms in our research. We annotated the OCT images with fovea and SCR instances to train the YOLO, FasterRCNN, and DETR models. However, as these algorithms are designed to process 2D images instead of 3D sequences, which is not the case with OCT volumes, we treated each B-scan as an independent entity. To assess the effectiveness of these models, we used average precision and recall metrics. Our results revealed the limitations of these algorithms in accurately detecting SCR instances, motivating us to develop our own deep learning solution.
More details in our paper.
Video, poster, and other resources in supplemental materials.
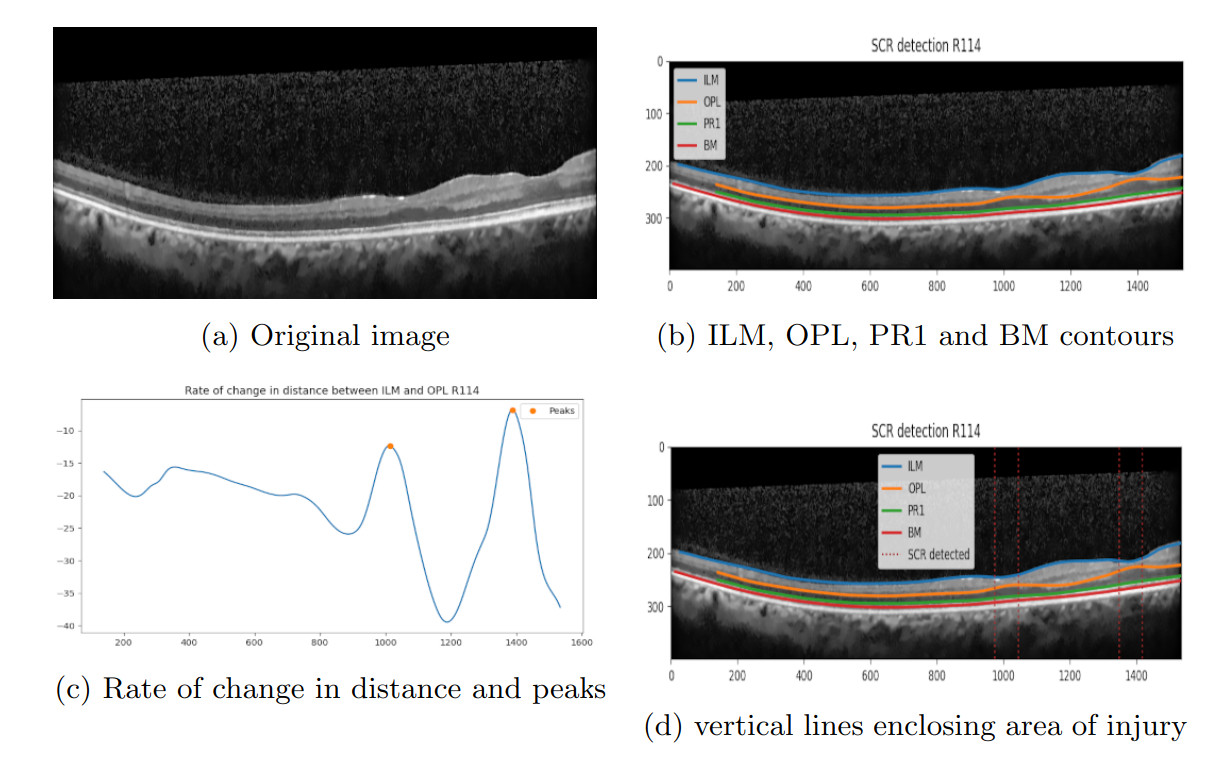
Multilevel Gradient method: Sickle Cell Retinopathy (SCR) is typically detected through a manual analysis of the change in thickness between the Internal Limiting Membrane (ILM) and Outer Plexiform Layer (OPL) of a B-scan. Affected areas exhibit a thinner distance between the ILM and OPL layers than adjacent non-affected areas. To circumvent the limitations of manual diagnosis, we have implemented a Multilevel Gradient-based approach, involving basic mathematical techniques without using advanced machine learning techniques. Our approach involves first obtaining contour maps of the B-scans using CU-Net. Subsequently, we calculate the distance between the ILM and OPL layers across the image width and analyze the rate of change in the distance, along with the points of maximum changes or peaks. We then individually examine the ILM and OPL layers to assess upward and downward concavity in the slopes of their curves, respectively. We repeat this process on multiple resolutions of the original curves, and identify the intersection of all the peak values to determine the areas with the highest likelihood of SCR instances. This approach significantly enhanced the diagnostic capabilities for SCR, paving the way for more efficient and robust methods involving deep-learning.
Relevant resources in supplemental materials.